智能数字世界
学习与研究最新的智能数字世界技术,计算机视觉、自然语言处理、跨模态学习、自监督学习、智能体、机器人、元宇宙。
数据集列表
CIFAR-10
CIFAR-10数据集有10个类,总计60000个彩色图像,每类5000个训练图像与1000个测试图像,图像尺寸为32*32,类别包含飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车。有5个训练批,每一批10000张图,另外10000用于测试,单独构成一批。是由Alex Krizhevsky、Vinod Nair、Geoffrey Hinton收集。
大小:171M
用途:图像分类
CIFAR-100
CIFAR-100数据集有100个类,总计60000个彩色图像,每类有500个训练图像与100个测试图像,尺寸为32*32,分为20个超类,每个超类包含5个类,每个图像都有一个“精细”标签(它所属的类)和一个“粗糙”标签(它所属的超类)。 是由Alex Krizhevsky、Vinod Nair、Geoffrey Hinton收集。
大小:161M
用途:图像分类
MNIST
MNIST 是一个手写数字集,包含0~9标签,总计65000个灰度图像,每个数字5500个训练图像和1000个测试图像,尺寸为28×28,图像为黑底白字,训练集由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局的工作人员, 测试集也是同样比例的手写数字数据,数据集来自美国国家标准与技术研究所。
大小:50M
用途:图像分类,数字识别
PennFudanPed
这是一个图像数据集,共有170幅图像,用于目标检测、图像分割。这些图片取自校园和城市街道周围的场景,我们对这些图像感兴趣的对象是行人。每个图像中至少有一个行人。其中有345名行人,其中96张来自宾夕法尼亚大学周边,另外74幅来自复旦大学周边。
大小:52M
用途:行人检测、图像分割
VOC
PASCAL VOC数据集共计17125幅图,11540幅图用于目标检测,包含训练集5717幅与测试集5823幅,4个大类vehicle、household、animal、person,共包含20个小种类。
大小:1.9G
用途:目标检测、语义分割
COCO
COCO数据集是一个大型的、丰富的物体检测,分割和字幕数据集。图像包括80类,328000影像,2017训练集有118287个图像,2017测试集有40670个图像,2017验证集有5000个图像,这个数据集以scene understanding为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的segmentation进行位置的标定,有目前为止有语义分割的最大数据集,COCO数据集由微软于 2014 年发布。
大小:25G
用途:目标检测、语义分割、全景分割、人体关键点检测、图像描述生成
ImageNet
ImageNet数据集有1400多万幅图片,涵盖2万多个类别。是根据WordNet层次结构组织的图像数据集。WordNet中的每个有意义的概念,可能由多个单词或词组描述,称为“同义词集”或“synset”。WordNet中有超过100000个语法集,其中大部分是名词(80000+)。在ImageNet中,我们的目标是平均提供1000张图像来说明每个synset。每个概念的图像都经过质量控制和人工注释。在它的完成中,我们希望ImageNet能够为WordNet层次结构中的大多数概念提供数以千万计的干净排序的图像。ImageNet数据集由斯坦福大学的李飞飞等人于 2009 年在视觉科学学会首次发布。
大小:150G
用途:图像分类
模型列表
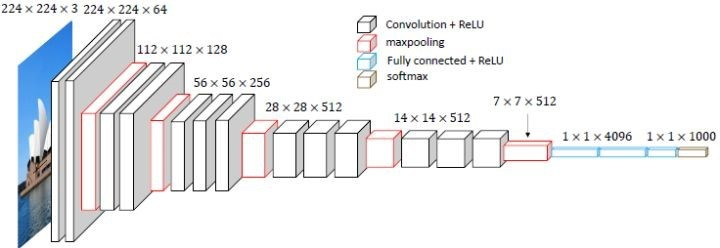
VGG
VGG由牛津大学的视觉几何组(Visual Geometry Group)提出,是ILSVRC-2014中定位任务第一名和分类任务第二名。其突出贡献在于证明使用小的卷积(3*3)组合比一个大滤波器(5x5或11x11)卷积层效果要好,验证增加网络深度可以有效提升模型的效果,而且VGG具有很好的泛化能力。作者为Karen Simonyan, Andrew Zisserman。
论文地址:https://arxiv.org/abs/1409.1556
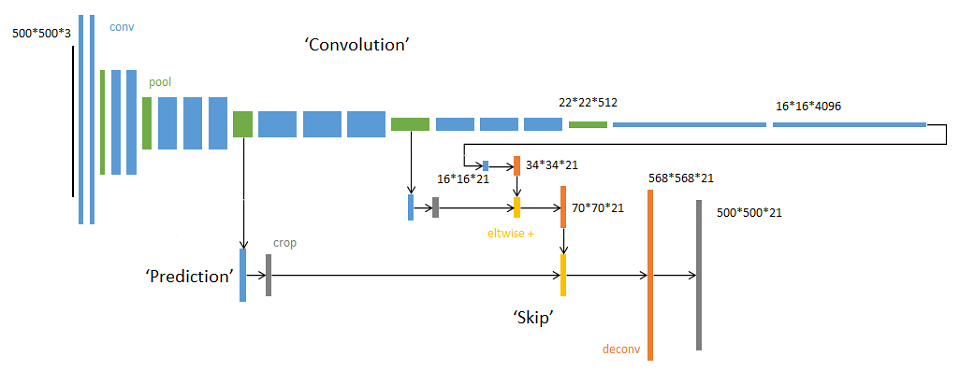
FCN
全卷积网络(Fully Convolution Network, FCN),可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 并定义一个跳跃结构,它将来自深层、粗糙的语义信息与来自浅层、细致的外观信息结合起来,从而生成精确而详细的分割信息,最后在上采样的特征图上进行逐像素分类。作者为Jonathan Long, Evan Shelhamer, Trevor Darrell。
论文地址:https://arxiv.org/abs/1411.4038
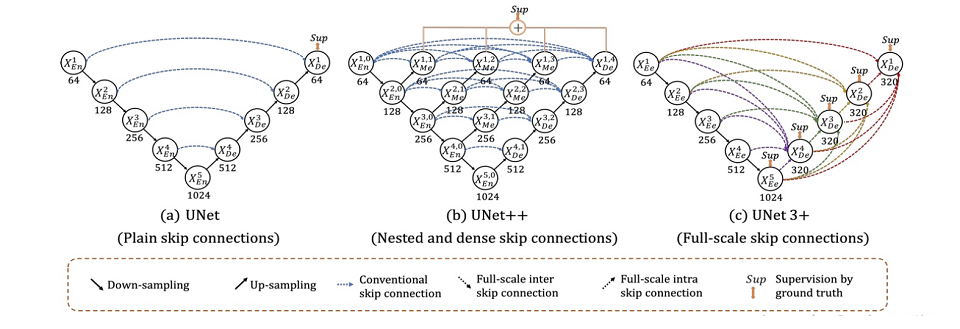
U-Net
U-Net主要是针对生物医学图片的分割,可以使它使用更少的训练图片的同时,且分割的准确度也不会差,UNet的encoder下采样4次,一共下采样16倍,decoder也相应上采样4次,skip connection采用的是channel维度拼接融合,将encoder得到的高级语义特征图恢复到原图片的分辨率,到目前为止已发展出多个新版本,作者为Olaf Ronneberger, Philipp Fischer, Thomas Brox。
论文地址:https://arxiv.org/abs/1505.04597
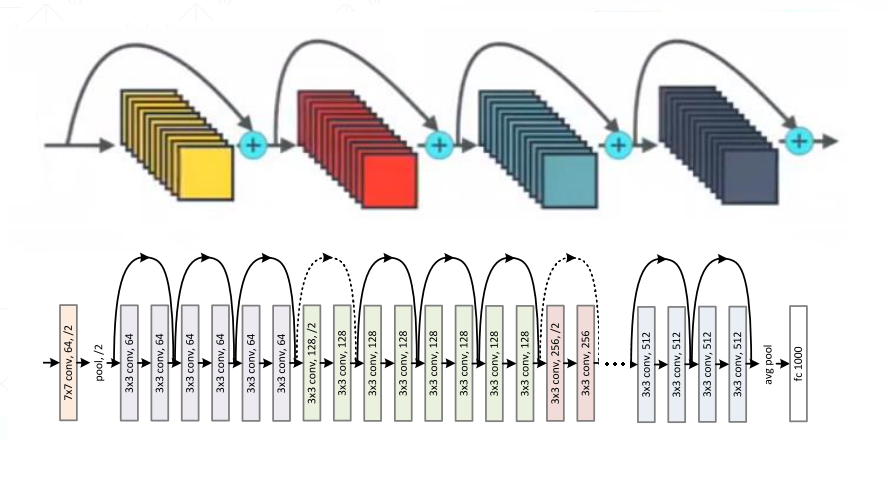
ResNet
ResNet残差网络是由来自Microsoft Research的4位学者提出的卷积神经网络,在2015年的ImageNet大规模视觉识别竞赛(ImageNet Large Scale Visual Recognition Challenge, ILSVRC)中获得了图像分类和物体识别的最佳。 ResNet的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题 。作者为Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun。
论文地址:https://arxiv.org/abs/1512.03385
Faster RCNN
Faster RCNN是经过R-CNN和Fast RCNN的积淀,在2016年提出,在结构上,Faster RCNN已经将特征抽取(feature extraction),proposal提取,bounding box regression,classification都整合在了一个网络中,使得综合性能有较大提高,在检测速度方面尤为明显。Faster rcnn使用RPN(region proposal network)卷积网络替代rcnn/fast rcnn的selective search模块,将RPN集成到fast rcnn检测网络中。作者为Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun。
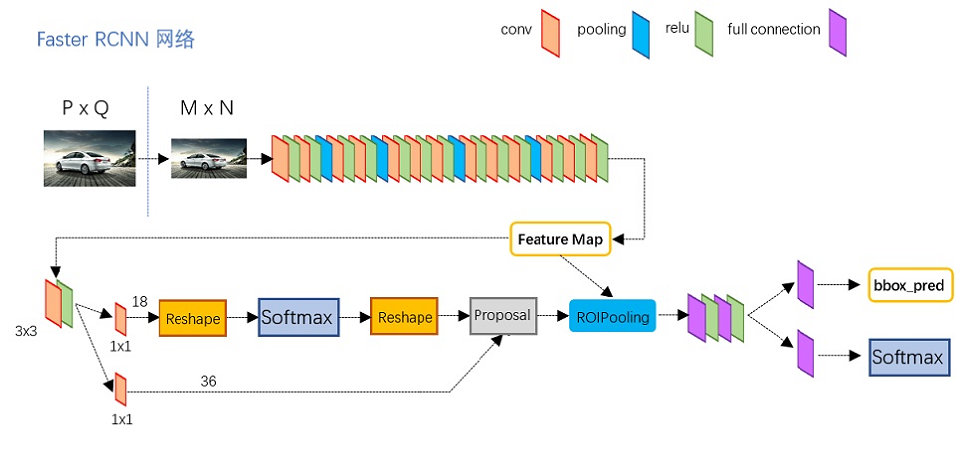
论文地址:https://arxiv.org/abs/1506.01497
YOLO
YOLO将物体检测作为回归问题求解。基于一个单独的end-to-end网络,完成从原始图像的输入到物体位置和类别的输出。YOLO将输入图像分成SxS个格子,每个格子负责检测‘落入’该格子的物体。若某个物体的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。YOLO特点:很快,基于整张图片信息进行预测,基于最新进展,到目前为止已发展出多个版本。作者为Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi。
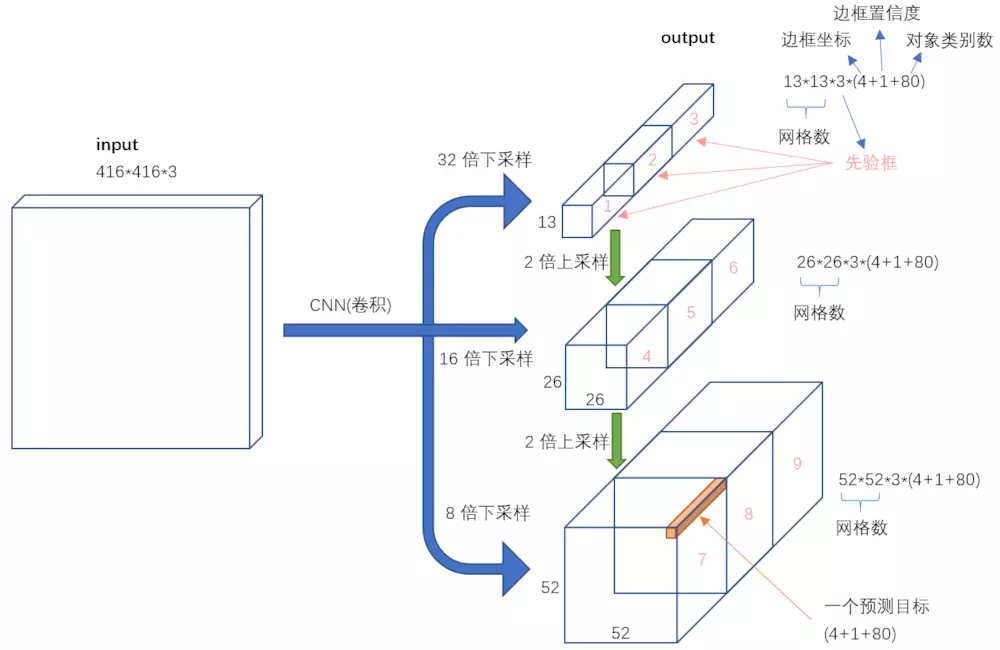
论文地址:https://arxiv.org/abs/1506.02640
DenseNet
DenseNet它的基本思路与ResNet一致,但是它建立的是前面所有层与后面层的密集连接(dense connection),它的名称也是由此而来。DenseNet的另一大特色是通过特征在channel上的连接来实现特征重用(feature reuse)。这些特点让DenseNet在参数和计算成本更少的情形下实现比ResNet更优的性能,DenseNet也因此斩获CVPR 2017的最佳论文奖。DenseNet主要特点:减轻了梯度消失,加强了feature的传递,更有效地利用了feature,一定程度上较少了参数数量。作者为Gao Huang(Cornell University)、Zhuang Liu(Tsinghua University)、Laurens van der Maaten(Facebook AI Research)、Kilian Q. Weinberger(Cornell University)。

论文地址:https://arxiv.org/abs/1608.06993
FPN
FPN(feature pyramid networks)特征金字塔网络。之前多数目标检测算法都是只采用顶层特征做预测,但我们知道低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而FPN不一样的地方在于预测是在不同特征层独立进行的。作者为Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, Serge Belongie。
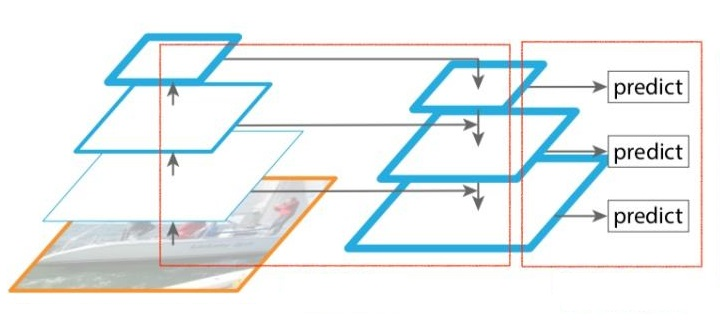
论文地址:http://arxiv.org/abs/1612.03144
Transformer
Attention Is All You Need是一篇Google提出的将Attention思想发挥到极致的论文。这篇论文中提出一个全新的模型叫 Transformer,抛弃了以往深度学习任务里面使用到的 CNN 和 RNN ,目前大热的Bert就是基于Transformer构建的,这个模型广泛应用于NLP领域,例如机器翻译,问答系统,文本摘要和语音识别等等方向。作者为Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin。
论文地址:https://arxiv.org/abs/1706.03762
HRNet
HRNet是中科大和微软亚洲研究院,发布了新的人体姿态估计模型,刷新了三项COCO纪录,还中选了CVPR 2019。HRNet的神经网络拥有与众不同的并联结构,可以随时保持高分辨率表征,不只靠从低分辨率表征里,恢复高分辨率表征。如此一来,姿势识别的效果明显提升:在COCO数据集的关键点检测、姿态估计、多人姿态估计这三项任务里,HRNet都超越了所有前辈。作者为Ke Sun, Bin Xiao, Dong Liu, Jingdong Wang。
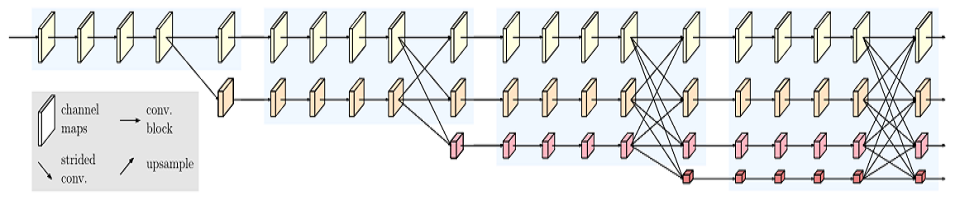
论文地址:https://arxiv.org/abs/1902.09212
Swin Transformer
Swin Transformer是一种新型视觉Transformer,它可以用作计算机视觉的通用backbone。Swin transformer是在每个local windows计算self-attention,并基于移动窗口构建的注意力模块,移动窗口的多头自注意力模块(shifted windows multi-head self attention, SW-MSA)和基于窗口的多头自注意力模块(W-MSA),其他的归一化层和两层的MLP与原来保持一致,并使用了GELU激活函数。作者为Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo。
论文地址:https://arxiv.org/abs/2103.14030
解决方案列表
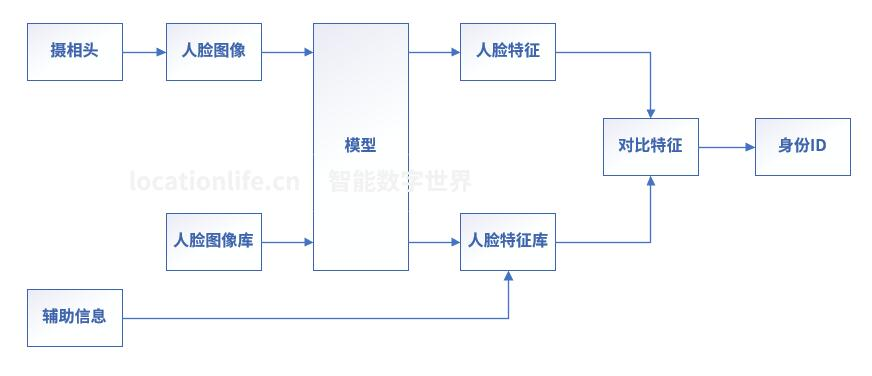
人脸识别方案
人脸识别方案,模型采用孪生神经网络,孪生神经网络包含两个子网络,子网络各自接收一个输入,将其映射至高维特征空间,并输出对应的表征。通过计算两个表征的距离,使用者可以比较两个输入的相似程度。
关于我们
智能数字世界网,目标是为开发者提供机器学习相关的数据、模型、方案。
通过邮箱jiangshulong@126.com联系我们。

